我如何构建 Claude Code 会话以确保代码顺利上线
一份实用的指南,介绍如何开启、运行和结束 Claude Code 会话,以确保 AI 助手保持正轨,并将产出顺利部署到生产环境。

我早期的 Claude Code 会话大多以同样的方式结束:代码虽然能运行,但我却无法解释 AI 到底修改了什么,导致我不敢提交代码。问题不在于模型本身,而在于我缺乏对会话过程的结构化管理。
在过去的几个月里,我总结出了一套可重复的 AI 编码会话模式,它能持续产出我可审查、可理解且可上线的代码。
会话开启前
最重要的工作发生在输入任何指令之前。如果你一打开 Claude Code 就说“修复这个身份验证错误”,你是在让 AI 替你定义问题。这通常不会有好的结果。
相反,请花两分钟写下:
- 用一句话准确描述哪里坏了或缺少了什么
- 哪些文件最可能涉及其中
- “完成”的标准是什么——即验收准则
这不需要很正式。在草稿文件中写个注释就行。关键在于,你在 AI 开始工作之前就已经做出了决定,而不是事后补救。
开启会话
从背景信息开始,而不是直接下指令。Claude Code 会自动读取你的 CLAUDE.md,但它不知道你昨天在做什么。一段简短的引导信息很有帮助:
我正在处理 middleware/auth.go 中的管理员身份验证流程。
问题:当 Authorization 请求头存在时,API 密钥验证被跳过了。
我希望在不触及 JWT 路径的情况下修复此问题。
然后,在要求 AI 进行任何修改之前,先让它读取相关文件。如果你直接跳到“编辑此文件”,AI 可能会做出看起来合理但忽略了实际约束的修改。
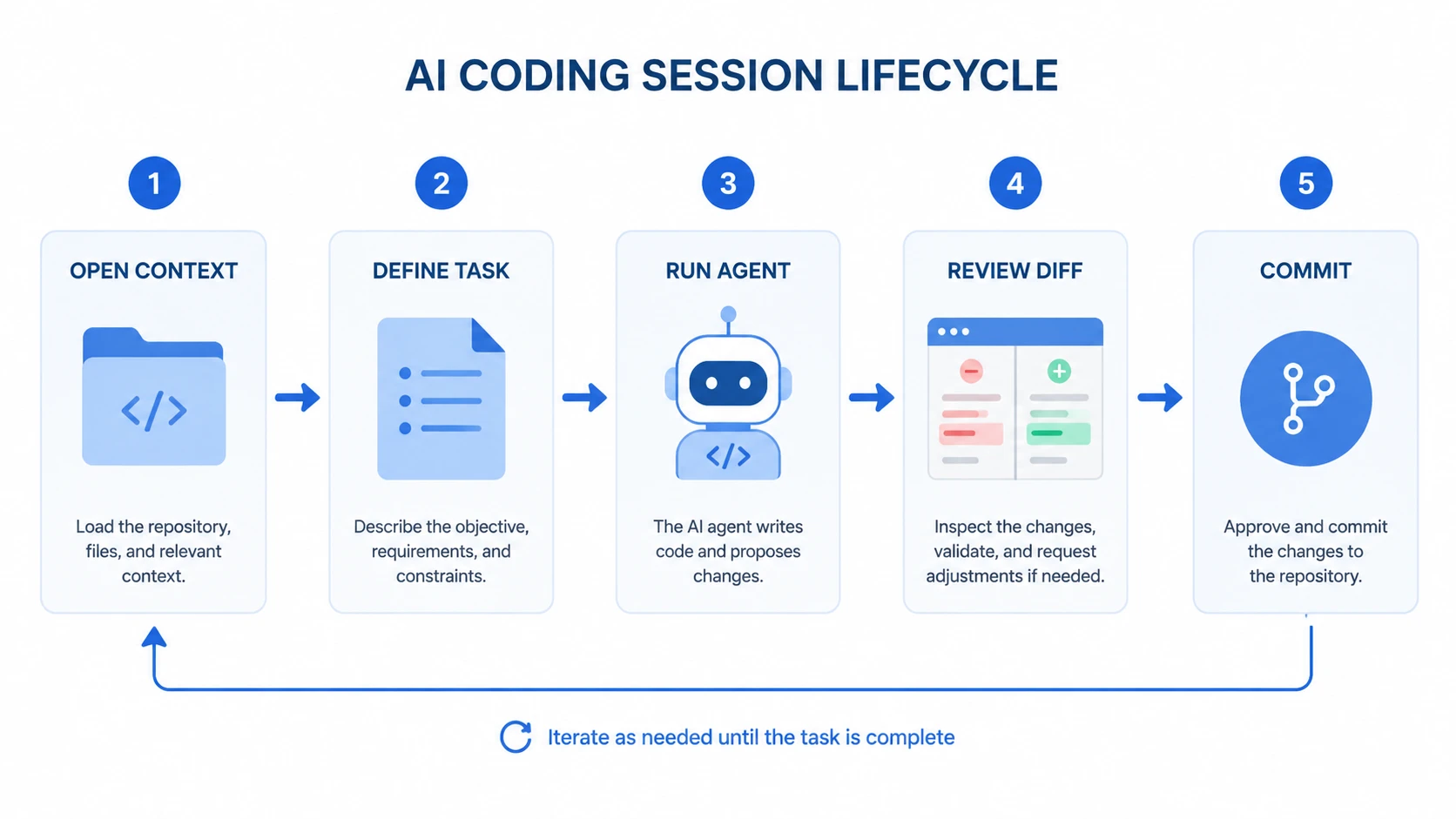
会话期间
保持任务范围紧凑。每个会话只处理一个逻辑变更是一个很好的经验法则。如果 AI 发现了相关问题——比如缺失的索引、未处理的错误或命名不一致——请将其记在别处,并专注于原始任务。在 AI 编码会话中,范围蔓延(Scope creep)会导致审查困难,且容易事后后悔。
观察工具调用,而不仅仅是输出结果。当 Claude Code 读取文件、检查定义或运行命令时,这些操作能告诉你 AI 是否理解了问题。一个在读取文件前就直接修改文件的 AI 通常是在瞎猜。
如果 AI 卡住了或开始重复自己,请停止并重新梳理。不要在一个混乱的会话基础上堆砌更多上下文。清除状态,用更窄的提示词重新开始。
审查输出
在接受任何更改之前,运行 git diff 并阅读每一行。这听起来显而易见,但当 AI 的总结听起来很有把握时,人很容易产生疏忽。AI 可能会产出看起来正确但实际上解决了错误问题的代码。
需要检查的事项:
- 修改是否在定义的范围内?
- 是否有不应存在的新的依赖项或导入?
- 修改是否破坏了相邻代码中明显的逻辑不变性?
- 是否留下了调试日志、注释掉的代码块或临时的“黑客”手段?
如果看起来不对劲,请让 AI 解释特定的一行,而不是重新运行整个任务。解释的成本很低,但进行第二轮编辑的成本很高。
结束会话
提交代码时,提交信息应捕捉意图,而不仅仅是修改了什么。“修复 AdminAuth 中间件中的 API 密钥验证顺序”比“更新 auth.go”更有用。提交信息是你记录该会话实际目的的地方。
如果会话产生了尚未准备好提交的草稿或部分工作,请使用 stash 或分支保存。不要无限期地保持 AI 会话开启,指望稍后再回来处理。上下文会退化,重新引导 AI 所花费的时间远比干净地结束并重新开始要多。
有效的模式
能够稳定上线的会话都有共同的结构:清晰的会话前定义、专注的范围、执行过程中的主动监控、仔细的差异审查以及干净的收尾。这些都不是 Claude Code 特有的。这与任何代码审查或结对编程中保持高效的纪律是一样的。
AI 代理带来的变化是速度。AI 可以快速产出大量内容,这意味着错误也会更快地累积。结构化管理正是防止这种速度成为负担的关键。